北京大学与深度求索联合开源大模型推理加速框架DSpark,旨在提升大语言模型高并发推理效率。DSpark通过双重优化机制解决响应延迟与算力浪费问题:候选生成阶段采用半自回归架构,并行输出高质量特征并优化逻辑;验证调度层面引入置信度调度,优先处理高可靠性文本片段。该框架仅需两层Transformer结构即可超越五层并行模型,有效平衡速度与质量,显著减少无效计算,提升对话实时
联合开源攻关高并发痛点
6月28日, 北京大学和深度求索正式宣告联合推出并且开源大模型推理加速框架, 此框架直接针对大语言模型高并发场景之中的响应延迟以及算力浪费难题, 该框架借助双重优化机制, 在候选生成以及验证调度环节达成突破, 为行业供给了一套切实可行的技术方案。
在传统的自回归生成流程里头, 每输出一个词元都得消耗全部算力, 这对对话实时性造成了限制。虽说推测解码是主流的提速办法, 然而传统方案的短板十分明显: 简单模型采用串行方式耗时很长, 并行模型在处理长序列时候选接受率会下降, 大量算力被白白消耗掉句号。
半自回归架构打破瓶颈
在候选生成的阶段之时, 框架创新地采用半自回归的架构, 借助并行主干网络一次性输出高质量的基础特征。轻量化模块仅仅只需两层结构就能够达到优于五层并行模型的表现, 在速度和质量之间获取到颇为巧妙的平衡。
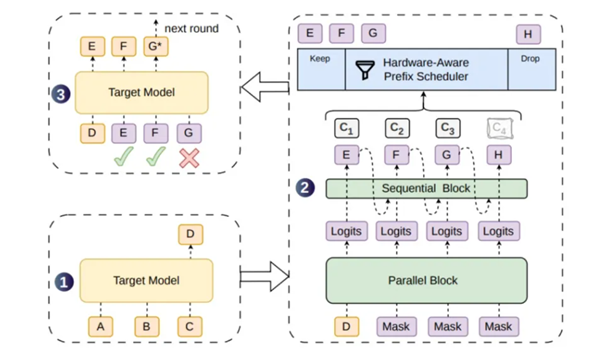
进行研发团队介绍, 此设计显著地将单次推理时间缩短了, 与此同时还确保了文本逻辑的连贯性。经过测试, 在代码编写以及数学推理等复杂任务当中, 框架的有效生成长度显著地比行业主流基线模型要好。
置信度调度减少无效计算
验证调度这个层面, 框架之中引入了置信度调度验证这样的机制,硬件感知前缀调度器会实时去判断算力负载, 该机制会优先处理可靠性高的文本片段, 最大限度降低无效计算, 提升整体推理效率。
根据实测得出的数据可表明, 和传统方法相比较而言, 框架于长序列生成任务里有效地减轻了候选有效率衰减这一颇为棘手的问题。这所蕴含的意义显示, 系统是能够在高并发环境状况下维持稳定输出的, 而且可以避免因算力出现浪费从而致使的响应延迟现象。
工程优化实现系统级提升
工程化落地这块, 研发团队开展了深度系统级优化, 其中有通过序列打包来减少内存消耗, 还有采用异步调度模式以消除GPU流水线卡顿。框架已然保证了对主流CUDA硬件生态的兼容性, 进而减低了部署门槛。
当下, 此框架已首先在-V4-Flash以及-V4-Pro预览版服务引擎处实现落地。种种数据表明, 于不同响应速度标准的状况之下, 系统整体的吞吐量均达成了跨越式的增长, 从而为高并发业务供应可靠的支撑。
开源降低行业部署成本
全套训练代码、模型权重以及评估工具, 已被深度求索在项目里进行开源, 这样的一个举措将会极大程度地削减行业高性能推理服务的部署成本, 从而为大模型低成本的普及提供技术范式。
业内专家觉得, 开源的策略能够助力加快技术的迭代, 使中小企业与巨头在推理性能方面的差距得以缩小。开发者能够依据这个框架迅速搭建有效率的推理系统, 促使AI应用向着规模化落地的方向推进。
多场景测试表现亮眼
历经通义千问3等主流模型于代码编写、数学推理以及日常对话等多个场景展开测试, 该框架所呈现出的表现极为亮眼,单轮有效生成长度拥有显著优势, 特别是在长序列生成任务里成效明显。
测试报告表明, 框架在多样硬件环境当中都能够维持稳定加速比, 证实了其通用性以及实用性, 随着更多企业接入进来, 这项技术有可能会变成行业新标准。
留意至此, 你觉得此项推理加速技术能不能切实化解AI落地的算力瓶颈难题呢? 欢迎于评论区去分享你的见解 , 将点赞和转发促使更多人知悉这一突破!
登录后参与评论
评论仅开放给已登录并完成邮箱绑定的用户。
0
暂无评论。