富士通推出PHOTON架构,旨在解决传统Transformer模型在处理长文本和高并发多查询任务时的性能瓶颈。PHOTON采用语义分层技术,避免频繁访存操作,降低计算复杂度并提升并行能力。其多查询决策环节通过“多数决定”或“最佳选择”策略实现单次推理结论,显著减轻GPU负担。测试显示,PHOTON在600M至1.2B参数模型中展现出高吞吐量与低
架构创新突破传统瓶颈
近日, 富士通的研发团队公开了一项创新架构, 这项架构名为“自上而下网络并行分层计算”, 其目的是解决传统深度学习模型在高复杂度场景下的性能瓶颈, 该架构借助对当前主流Transformer架构进行重新设计, 成功绕开了传统模型在处理长文本或者多任务并发时处的核心缺陷。
据悉, 富士通技术团队表明, Transformer架构尽管性能颇为强大, 然而在针对长序列或者高并发查询予以处理之际, 需要频繁开展显存读写操作来调取历史信息, 致使处理速度受到限制。这一所谓的“访存瓶颈”, 不但拖慢了推理效率, 而且还显著加大了GPU的计算负担。新架构却是从底层逻辑着手, 彻底扭转了这一状况。
分层机制优化并行效率
核心优势在于新架构的独特分层处理机制, 富士通引入了语义分层技术, 将文本或任务按语义单 元进行划分。此中方法有效降低了计算复杂度, 大幅提升了并行计算能力, 与其传统模型采用词元级分割方式不同。
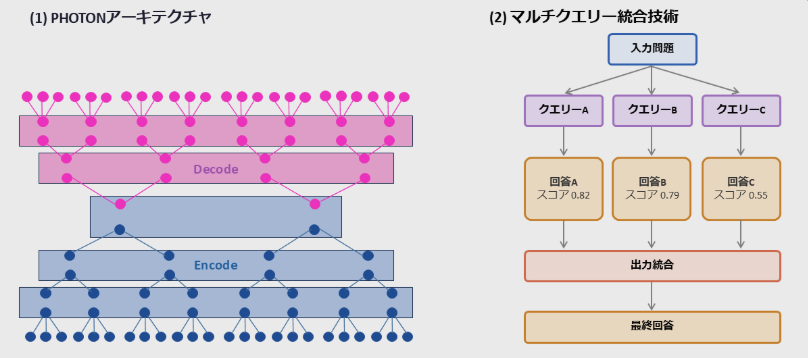
依据技术文档所呈现的内容, 该架构借助语义分层达成了任务的分解以及并行的执行, 进而避免了出现于传统模型当中因全局注意力机制而引发的高昂计算开销。于多查询任务的决策部分, 该架构采用了“多数决定”或者“最佳选择”的策略, 仅仅需要一次推理便能够得出结论, 极大程度地精简了流程。
测试数据展现惊人性能
富士通所公布的测试数据表明, 于参数规模为600M的小型模型里, 新架构呈现出了极高的吞吐量, 还展现出了极低的内存占用, 在参数规模为900M的小型模型中亦是如此, 在参数规模为1.2B的小型模型中同样如此。尤其是在参数规模为1.2B的模型之下, 其多查询处理性能达成了传统Transformer架构的475倍。
在同等硬件条件情形下, 这一数据所具有的意义在于, 新架构能够去处理远远超过以往的查询量。测试环境运用标准GPU集群, 显示出的结果是, 资源调度效率已然得到显著优化, 延迟大幅度降低。对于存在海量实时数据需要进行处理的那些应用场景, 像搜索引擎或者客服系统, 这一提升有着里程碑一般的意义。
优化智能体系统性能
因为该架构于每次迭代之际所需的KV Cache也就是键值缓存更少些了, 这便意味着系统能够去支持更高的迭代次数了。这针对需要大量I/O流程的智能体系统来讲呢,是一种巨大的性能增益了。
在智能体系统运行期间, 会频繁地去调用外部工具或者数据库, 此时数据读写操作特别容易变成瓶颈。新架构借助减少缓存占用这种方式, 释放出了宝贵的显存资源, 进而让系统能够更加高效地去执行多轮交互。富士通宣称, 这样的一种设计为复杂任务链的执行提供了技术方面的基础。
质量与效率实现平衡
虽然于部分指标方面, 新架构的质量稍微有所折损, 不过依靠其在计算效率之中的跨越式进步, 给降低AI运行成本提供了一种极具潜力的技术方案, 技术团队承认, 在极少的高精度任务里, 传统模型依旧占据优势。
然而, 就多数实际运用而言, 效率方面的优势要远远大于那微乎其微的精度损耗。富士通着重指出, 该架构的目标是为“成本敏感型”情形提供服务, 像边缘计算、移动端布置以及大规模API服务一类。通过削减推理成本, 企业能够凭借更少的硬件投入获取更快的响应速率。
推动技术应用落地
当下, 富士通正踊跃推进该架构的应用实现落地, 期望借由底层算法的革新, 给未来的智能化应用场景供应更轻便、更高效的底层支持。公司已和多家云计算厂商进行接洽, 探讨技术集成方案。
富士通从事研发工作的部门负责人宣称, 那种架构预估会在二零二六年的第四个季度步入试点时期。第一个应用的场景会着重于实时去进行翻译以及智能客服这两个领域。团队打算在二零二七年开始的时候开放一部分核心代码, 以此来吸引开发者群体一同进行优化。
你觉得, 这项有着475倍效率提升的创新, 能不能切实终结AI算力“卡脖子”的状况呢? 欢迎于评论区域展露出你的想法, 把点赞以及转发操作进行下去以便让更多人目睹到这一回的突破要点!
登录后参与评论
评论仅开放给已登录并完成邮箱绑定的用户。
0
暂无评论。