阿里 ATH-Token Foundry 与中国人民大学高瓴人工智能学院开源LOGOS模型,旨在弥合科学领域的数据鸿沟。该模型通过共享词表和离散Token序列,将蛋白质、小分子等异构对象统一编码,实现跨学科知识共享,无需依赖昂贵的3D信息。LOGOS以序列预测方式构建3D空间互作规律,建立通用“科学语法”,并在参数效率上表现优异,显著提升科研效率。
阿里联合人大开源LOGOS模型 破解跨学科数据孤岛难题
在6月18日的时候, 阿里巴巴ATH – Token团队同中国人民大学高瓴人工智能学院联合宣告, 正式把一款名为LOGOS的多领域科学生成基础模型进行开源。这一成果被业界看作是科学人工智能领域的重要转折点之所在, 原因是它首次针对蛋白质、小分子、材料等异构科学对象给出了一套统一的“科学语法”。以往, 不同科研分支的数据如同“语言不通”的孤岛一般, 如今它们终于能够实现高效对话了。
打破数据壁垒 从3D坐标到序列预测
长时期以来, AI身处科研应用里遭遇的关键痛点是, 数据格式并非整齐统一。蛋白质、小分子跟MOF材料等在结构方面差异显著, 传统办法依赖繁复的3D坐标或者专门的几何神经网络来加以处理。这不但致使计算成本高昂, 并且当模型转向另一个研究领域时, 就得重新进行训练。LOGOS模型借由设计一套共享词表, 把这些异构对象统一编码成离散的Token序列, 达成了“读文字”样式的建模方式, 决然告别了贵气的3D空间依赖。
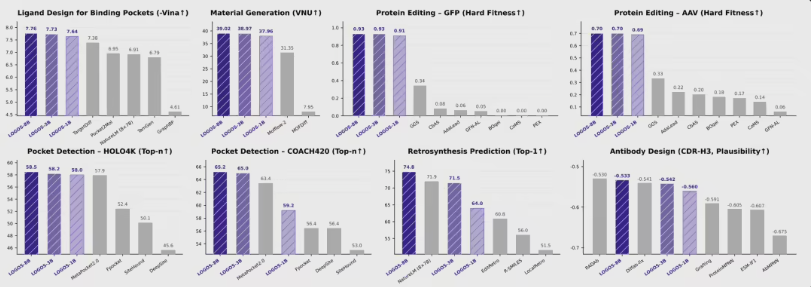
参数效率惊人 1B模型性能超越微软方案
就性能层面而言, LOGOS – 1B版本呈现出极高的参数效率, 依据项目组所公布的数据, 该模型仅仅使用微软同类模型1/56的参数量, 就在多项具有代表性的科学任务里达成了性能上的超越, 这表明, 科研人员并不需配备顶级的算力资源, 也能够运行高性能的科学模型, 除此之外, LOGOS解决了预训练与下游任务之间的“目标偏差”问题, 模型不用繁琐的微调就能够直接用于生成任务, 极大地降低了AI在科研领域的应用门槛。
超大规模语料库支撑 7类模态全覆盖
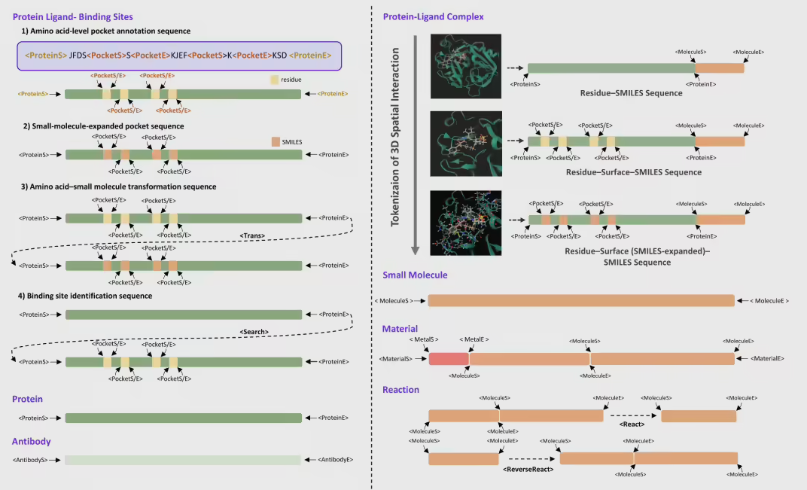
当下, LOGOS已然搭建起了超大规模预训练语料库, 这一语料库涵盖7类模态, 一共有44.87B参数。那语料库里的数据作了多方面覆盖, 像蛋白质序列, 还有抗体结构, 以及小分子化学式, 甚至MOF材料等等多种科学对象。项目组宣称, 此语料库的规模与多样性, 给模型学习跨领域的“科学语法”奠定了坚实基础。凭借在海量异构数据上开展预训练, LOGOS能够自行发觉不同科学对象之间的深层关联。
全面开源 降低科研自动化门槛
项目组已把LOGOS的模型权重、推理代码以及详尽的技术报告进行了全面开源, 目的是让更多科研团队从中受益, 开发者能够通过指定渠道去下载以及使用, 这一举措表明, 不管是高校实验室还是初创企业, 都能够直接依据LOGOS来开展二次开发,而用不着从零开始构建复杂模型, 这被看作是推动科研自动化的关键一步, 特别是在新药研发、材料设计等领域, 会显著缩短研发周期。
树立新范式 科学大模型走向通用化
有专家进行分析之后得出这样一种看法, LOGOS的开源意味着多模态科学大模型开发进入到了一个新的阶段, 以往的时候, 模型常常是针对单一任务去加以定制的, 其通用性比较差, 然而LOGOS借助统一的Token序列设计, 达成了跨领域知识共享, 为未来更具通用性质的科学AI奠定下了技术范式, 随着更多科研团队接入这一底层技术, 科学界的数据“语言”有希望变得从来没有过的统一以及高效。
互动进行提问, 你觉得统一的那种“科学语法”会率先在哪个领域造成颠覆性的突破——是药物研发这个领域, 又或者是新材料发现这个领域? 欢迎在评论区去分享你的看法, 点赞以及转发能让更多人知晓这一进展!
登录后参与评论
评论仅开放给已登录并完成邮箱绑定的用户。
0
暂无评论。